
 快播伦理电影网站
快播伦理电影网站
作家 | Eduardo Blancas
一个月前,OpenAI 在其 API 中新增了结构化输出功能,这意味着 OpenAI 当今大略字据开垦者提供的 JSON 模式,准确地生成恰当要求的输出杀青。我看到了这个功能之后,对此尽头感兴致,因此决定试用一下,并开垦了一个 AI 提拔网页执取用具。本文将转头我的学习效果,也但愿对宇宙有所裨益。
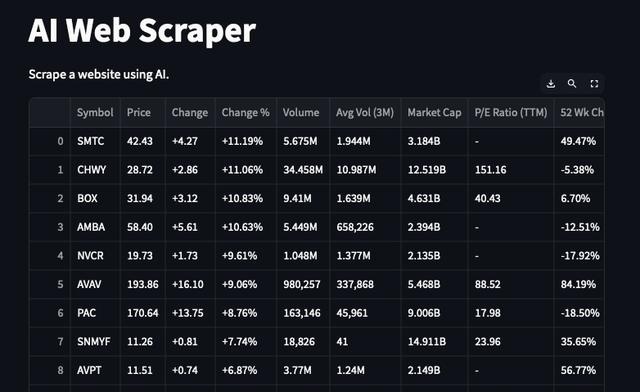

要求 GPT-4o 执取数据
激情网站第一个实验是径直要求 GPT-4o 从 HTML 字符串中提真金不怕火数据,因此我使用了新的结构化输出功能和以下 Pydantic 模子(https://docs.pydantic.dev/latest/):
from typing import List, Dictclass ParsedColumn(BaseModel):name: strvalues: List[str]class ParsedTable(BaseModel):name: strcolumns: List[ParsedColumn]
使用的 Prompt 是:
你是又名收集爬虫巨匠。当今给你一张包含表格的 HTML 履行,你必须从中提真金不怕火结构化数据。
底下是我在明白不同表格时发现的一些酷爱时事。
注:我也试过 GPT-4o mini,但杀青昭着比 GPT-4o 差,是以我继续使用 GPT-4o 进行实验。

明白复杂表格
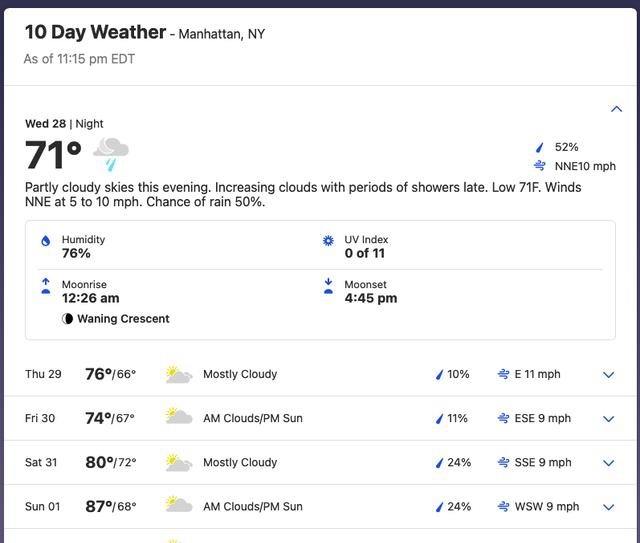
在对一些简便的表格进行实验后,我想望望模子在处理更复杂的表格时会有若何的阐明,因此我使用了 Weather.com 提供的 10 天天气预告。该表的顶部有一大行,用来展示本日的天气,其余 9 天所使用行数占得空间较小。酷爱的是,GPT-4o 大略正确明白:
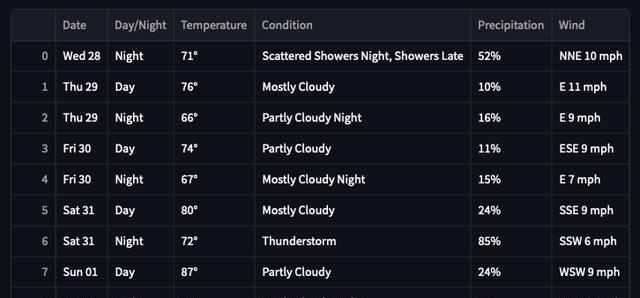
关于剩下的 9 天天气预告,表格真切了日夜预告(见上头的截图)。模子正确明白了这些数据,并添加了日/夜列。底下是它在浏览器中的真切效果(防备,要真切这个效果,咱们需重点击每一瞥右侧的按钮):
来源,我以为我出现了幻觉,因为我在网站上莫得看到 “条目”(Condition)一栏,但在巡视源代码后,我刚毅到这些标志是存在的,但在表格中看不到。

合并行会交集模子
当我想考在那处不错找到简便的表格时,我领先意象的是维基百科。杀青发现,维基百科上的一个简便表格(东谈主类发展指数)交集了模子,因为它具有重迭值的行被合并了:

天然模子大略检索单个列(按照系统 Prompt),但它们的大小并不调换,因此,我无法将数据默示为表格。
我尝试使用以下模式修改系统 Prompt:
表格可能会将多行折叠成一瞥。要是是这种情况,请将折叠的行提真金不怕火为多个 JSON 值,以确保总共列齐包含调换数目的行。
但它不起作用。我还莫得尝试修改系统 Prompt 来告诉模子提真金不怕火行而不是列。

要求 GPT-4o 复返 XPaths
每次运转 OpenAI API 调用可能会尽头奋斗,因此我认为应该让模子复返 XPaths 而不是明白后的数据。这么我就不错执取吞并页面(举例取得更新后的数据),而无需消耗太多。
经由一些调理后,我想出一个 Prompt:
你是一位收集爬虫巨匠。
用户将提供 HTML 履行和列名。您的任务是想出一个 XPaths,以复返该列的总共元素。
XPaths 应该是一个字符串,不错通过 Selenium 的 driver.find_elements(By.XPATH, xpath) 方法进行评估。
复返完好匹配的元素,而不单是是文本。
缺憾的是,这种方法效果欠安。偶然,模子会复返无效的 XPaths(尽管使用提到 Selenium 的句子不错缓解这种情况),或者 XPaths 会复返不正确的数据或根柢没非常据。

连合两种方法
我的下一个尝试是将两种方法连合起来:一朝模子提真金不怕火了数据,咱们就不错将其算作参考,向模子央求 XPaths。这比径直央求 XPaths 效果好得多!
我防备到偶然生成的 XPaths 根柢不会复返任何数据,因此我添加了一些愚蠢的重试逻辑:要是 XPaths 莫得复返杀青,则重试。这对我测试的表格很有用。
磋议词,我防备到一个新问题:偶然第一步(提真金不怕火数据)会将图像改变为文本(举例,指进取方的箭头可能会在提真金不怕火的数据中真切为“箭头进取”),这会导致第二步失败,因为它会查找不存在的数据。我莫得尝试贬责这个问题。

GPT-4o 太奋斗
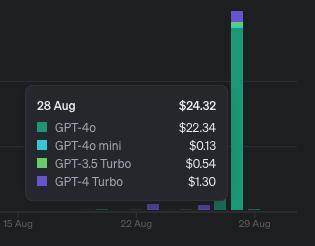
使用 GPT-4o 进行执取可能会尽头奋斗,因为即使是袖珍 HTML 表也可能包含深刻字符。我一经教练了两天,一经花了 24 好意思元!
为了裁汰资本,我添加了一些算帐逻辑,在将 HTML 字符串传递给模子之前,删除其中无须要的数据。一个简便的函数不错删除除 class、id 和 data-testid 以外的总共属性(我防备到生成的 XPaths 正在使用这些属性),将表中的字符数减少了一半。
我莫得看到任何性能下落,况且我怀疑此举也有助于晋升提真金不怕火质地。
目下,第二步(生成 XPaths)对表中每个列进行一次模子调用,另一个修订可能是生成多个 XPaths,我还莫得尝试这种方法并评估性能。

论断和演示
GPT-4o 的执取质地让我有些吃惊(但当我看到我必须向 OpenAI 支付具体若干钱时,我又合计景仰)。尽管如斯,这是一个酷爱的实验,我如实看到了东谈主工智能提拔网页执取用具的后劲。
我使用 Streamlit 作念了一个快速演示,对此感兴致的小伙伴不错通过下方连气儿巡视:https://orange-resonance-9766.ploomberapp.io,源代码在 GitHub 上:https://github.com/edublancas/posts/tree/main/ai-web-scraping。
我想测试更多的表格快播伦理电影网站,然则,由于这会波及到更高的 OpenAI 用度,是以我只尝试了其中的少数几个。